aws-advanced-jdbc-wrapperでハマったこと
ZOZO Advent Calendar 2023 カレンダー Vol.5 の 20 日目の記事です。
12/20は今年家族となった黒トイプードルの1歳の誕生日で、記念すべき日にアドベントカレンダーを書くことにしました。
Happy Birthday!!

aws-advanced-jdbc-wrapperとは
AWS Aurora MySQLを利用されている方は大変多いかと思いますが、aws-advanced-jdbc-wrapper(以下、jdbc-wrapper)はご存知でしょうか?
AWSが開発しているOSSで既存のJDBCをラップしてクラスター化されたAuroraを安全・安心、そして便利になるようにするドライバです。
プラグイン形式で必要に応じて各種機能を追加することができます。代表的なプラグイン1は以下になります。
| 機能名 | 概要 |
|---|---|
| フェイルオーバー接続プラグイン | Aurora クラスターおよび RDS Multi-AZ DB クラスターにおいてフェイルオーバー後に古いノードに接続するこを防ぐ |
| ホスト監視プラグイン | ホスト接続障害監視。より高速な障害検知を可能にする |
| IAM認証接続プラグイン | IAMを利用してAuroraクラスターに接続できるようにする |
| AWS Secrets Manager 接続プラグイン | Secrets Manager サービスからデータベース認証情報を取得 |
| 読み書き分割プラグイン | データベースのリーダーとライターのインスタンスを切り替える |
MySQLに特化したものではありますが、aws-mysql-jdbcというドライバもあります。jdbc-wrapperの方が後発になっており、プラグイン機能によってより強力になっているものと思います。
試してみる
次の環境で接続を行います。
jdbc-wrapperの設定はapplication.yamlに定義するだけで特段難しいことはありません。
spring: datasource: url: jdbc:aws-wrapper:mysql://{クラスタエンドポイント}/test driver-class-name: software.amazon.jdbc.Driver type: com.zaxxer.hikari.HikariDataSource hikari: data-source-properties: wrapperPlugins: readWriteSplitting,failover,efm readerHostSelectorStrategy: leastConnections failoverMode: reader-or-writer exception-override-class-name: software.amazon.jdbc.util.HikariCPSQLException
設定内容はマニュアルを見ていただくほうが良いかと思いますが、簡単に概要を説明します。
| プロパティ | 概要 |
|---|---|
spring.datasource.url |
JDBC URLにjdbc:aws-wrapper:mysqlを付与することでwrapperの利用を宣言する |
spring.datasource.driver-class-name |
wrapperのドライバクラスとしてsoftware.amazon.jdbc.Driverを設定する |
spring.datasource.hikari.data-source-properties.wrapperPlugins |
プラグインをカンマ区切りで指定 |
spring.datasource.hikari.data-source-properties.readerHostSelectorStrategy |
Auroraクラスタに複数のリーダーが接続している場合にどのように接続先を選択するかを指定 |
spring.datasource.hikari.data-source-properties.failoverMode |
フェイルオーバー時の挙動を指定 |
spring.datasource.hikari.exception-override-class-name |
コネクションプールがフェイルオーバー時に例外をハンドリングするために指定 |
これでbootRunを行えばMySQL Connector/Jと変わらずAuroraに接続することができます。jdbc-wrapperはAuroraを監視してくれており、定期的に障害が起きていないかSQLを実行して確認してくれています。
動かしてみよう
hogeテーブルから条件に合致する全件数と先頭5件を取得するロジックを組んでみます。細かい実装は省いていますがページング的な動きです。
sql_calc_found_rowsやfound_rows()はMySQL8以降、非推奨になってしまいましたが利用されている方は多いのではないでしょうか?便利なので利用させてもらいます。
雑に説明するとsql_calc_found_rowsはlimitを無視して件数を取得してくれる宣言で、found_rows()はそのLimitを無視した件数を取得する関数になります。
@RestController @RequestMapping( value = "/hoges", produces = {"application/json"}) public class HogeController { private final HogeService hogeService; public HogeController(HogeService hogeService) { this.hogeService = hogeService; } @GetMapping public ResponseEntity<HogeResponse> getHoges() { return ResponseEntity.ok(hogeService.getHoges()); } } @Service public class HogeService { private final JdbcTemplate jdbcTemplate; public HogeService(JdbcTemplate jdbcTemplate) { this.jdbcTemplate = jdbcTemplate; } public HogeResponse getHoges() { var list = jdbcTemplate.query( """ select sql_calc_found_rows id, message, point from hoge where point > 5 order by point desc limit 5 """, (rs, rowNum) -> new HogeEntity( rs.getInt("id"), rs.getString("message"), rs.getInt("point") ) ); if (list.isEmpty()) { return new HogeResponse(0, emptyList()); } var allCount = jdbcTemplate.queryForObject( """ select found_rows() """, Integer.class ); return new HogeResponse(allCount, list); } }
実行結果はこんな感じ。
❯ curl http://localhost:8080/hoges | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 212 0 212 0 0 1109 0 --:--:-- --:--:-- --:--:-- 1145
{
"allCount": 2,
"data": [
{
"id": 275,
"message": "177",
"point": 10
},
{
"id": 253,
"message": "42",
"point": 10
},
{
"id": 249,
"message": "87",
"point": 10
},
{
"id": 237,
"message": "333",
"point": 10
},
{
"id": 182,
"message": "244",
"point": 10
}
]
}
おや?
ポケモンが進化するような雰囲気ですが、上記の結果に違和感を覚えた方もいるかと思います。
dataは5件あるのにallCountが2になっていて結果に不整合が起きています。
これはfound_rows()とjdbc-wrapperの組み合わせで稀に起きる事象です。
found_rows()は最後にSELECTした行数をカウントする関数です。一方のjdbc-wrapperはAuroraの障害検知のために定期的にSQLを実行し監視を行ってくれます(発行されるSQLはこちら)。
勘のいい方ならお気づきでしょう。
そうです、sql_calc_found_rowsとfound_rows()の間でjdbc-wrapperの障害検知SQLが実行されていたのが原因でした。取得された2件はAuroraクラスタに接続されているRead・Writeの2台という意味になります。
対策はSELECT COUNTにすることで解消することができます。found_rows()はMySQL8から非推奨となっているので利用は避けるべきですね。
さいごに
発生頻度も低く特定に困難な事象でしたので、発見するまでにだいぶハマってしまいました。。
わかってしまえばなんてことないですが、ページング機能はORマッパーでサポートしていて内部的にfound_rows()を利用しているものもいくつかあるようです。
そういった場合は問題の特定に時間がかかってしまったりするので、この記事をしくじり先生として覚えておいていただけると自分の失敗も救われます。
デスクガジェット更新
ほぼ1年ぶりの更新。
今年はプライベートの時間が全く取れておらず、自己啓発的な活動ができなくてブログネタがなかった。。
そして連続ガジェット紹介になってしまいました。
前回の記事
chichi1091.hatenablog.jp
早速今回追加したものを紹介していきます
トリプルモニター化
余っていたiiyamaの24インチモニターを右上に設置してみました。
前まではデスクトップは2画面だったのが3画面になり、モニターをブラウザ専用や、IDE専用にしたり世界が広がりました。やはりモニターは何枚あってもいいですね。

モニターライト

目が疲れることが多く手元の明るさがほしいと思い購入。ワイヤレス操作でON・OFFができるのでよきです。ただ、目の疲れは変わらないのはちょっと残念。。
wi-fiルーター

我が家のwi-fiはリビングに設置されており、作業部屋からの接続だと切れることがちょいちょいあったので部屋に設置。普通に使えてます。
トラックボールマウス

デスクトップで利用していたマウスのスクロールがちゃんと動かないことがあり購入。初めてのトラックボールマウスということもあり使いこなせない。。カーソルの細かい動きが難しいし、補助ボタン(ブラウザの進む・戻る)が手が小さいのか親指が届かいと不満が。。。慣れの問題なんだろうから使い続けようと思います。
フルリモートワーカーとしてデスクガジェットはだいぶ揃って来たかな?
仕事用のmacとデスクトップ用とで分けて利用しているキーボードを一つにまとめるために、usbでも使えるHHKBに更新したい。
が、予算の都合上もうちょい先かな。。

ワイドモニターを導入して縦設置にしてみた
1年ぶりのPCネタ。
前回の記事はコチラ
chichi1091.hatenablog.jp
今回はワイドモニターを購入し、モニターアームも新調して縦2画面構成にしてみた。
購入したものは
japannext.net marantzpro.jp www.greenhouse-store.jp
色々調べているうちにJapanNextのモニターが勝手にウルトラワイドだと思い込んでいたようで、設置して接続してなんか違う。。ってなってしまった。
そうだよな。。この値段でウルトラワイド変えるわけないよなー。しかもUSBハブ機能もついているし。
※ウルトラワイドの解像度は29インチだと2560×1080みたいなので、これもウルトラワイドモニターのようでした。
でも購入の決め手になったのは値段の他にこのUSBハブ。
本業PCとプライベート兼副業自作PCのカメラやマイクが片方でしか使えなくていい方法ないかなーと思っていたところにモニター自体にハブがある機種があると知って購入を決めたので、これはサイコー。かんたんに切り替えができるのでこれから重宝しそう。
モニターアームは今まで横に並べていたモニターを見るのに結構首を動かす必要があってそのせいで肩こりとか起きてる気がしてので、縦設置に切り替えてみた。
これも成功で、首よりも机が広く使えるようになり、整理もしやすくなった。
上のモニターを見るのも動かす範囲が狭くなったので、これから期待。
今まで使っていたマイクがアームセットで2000円ぐらいだったためか、副業で声が聞こえないとかノイズがひどいとか色々言われていたため、購入を決めて適当に選んだ。
今の所苦情は来ていないので問題ないと思われるので、本業でも試していこうと思う。
完全なリモートワーカーになったので、自宅環境をアップグレードさせてきたけど次はネットワーク系になるのかな?
wi-fiを部屋に設置する感じかなー。嫁のチェックがあるので時間をおいてからかな。。

SpringBoot+JPAからTiDBを使ってみる
ZOZO Advent Calendar 2022 カレンダー Vol.3 の 15 日目の記事です。
前回はTiDBとMySQLの機能比較を行いました。
今回はSpringBootとJPAを利用してTiDBに接続するための方法や注意点を整理していきたいと思います。
環境
以下の環境で動作確認を行いました。
TiDBをDockerで起動する
こちらを参照にさせていただきdocker-compose.yamlを作成しました。
v5.4.0を利用していますが、M1 Macで動かす場合はv6.1.0にする必要がありましたのでご注意ください。
それぞれのコンテナの役割は次の図が参考になると思います。
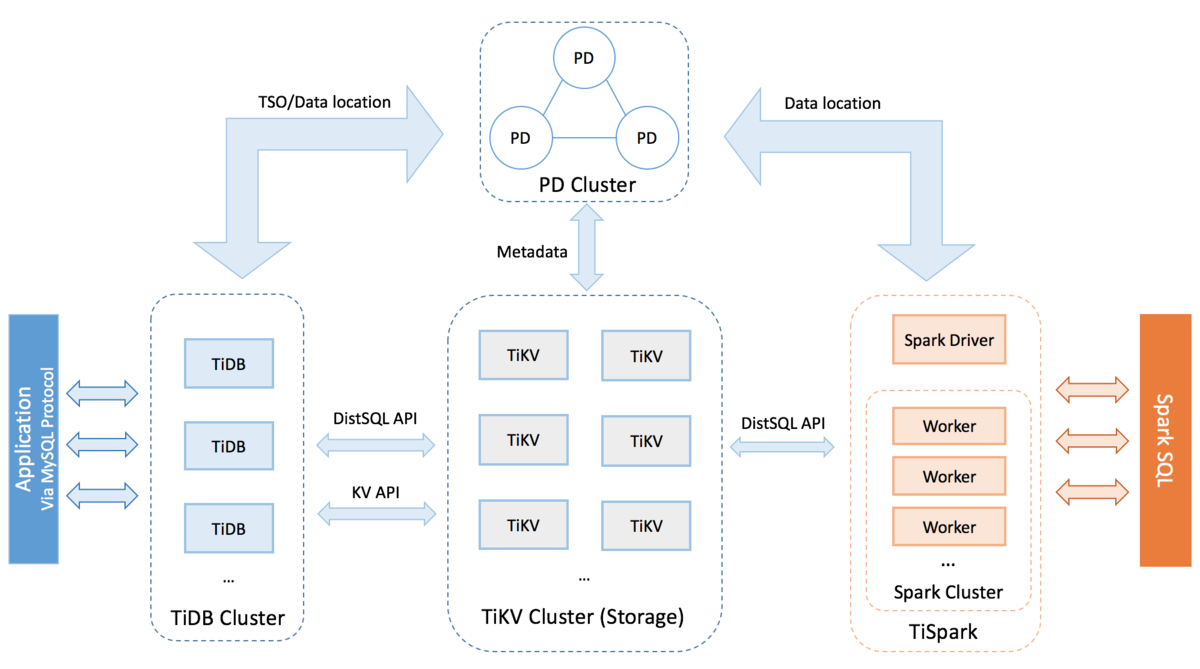
起動をしたらデータベースとユーザを作成していきます。さすがMySQL互換のTiDB、コマンドはMySQLのコマンドと同じ。なのでMySQLユーザであればおなじみのコマンドになります。
$ mysql -h 127.0.0.1 -P 4000 -u root mysql> create database tidb_sample CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; Query OK, 0 rows affected (0.10 sec) mysql> create user tidb@'%' IDENTIFIED by 'tidbpassword'; Query OK, 0 rows affected (0.02 sec) mysql> GRANT ALL PRIVILEGES ON * . * TO tidb@'%'; Query OK, 0 rows affected (0.02 sec)
これでTiDBの準備は完了です。MySQL Workbenchなどで接続をしてみてください。
SpringBoot
TiDBはMySQL互換なので、HibernateのMySQL dialectで接続することができるのですが、PingCAP社が作成したTiDB dialectを利用するとTiDB独自のWindow関数などの利用が行えるようになります。TiDB dialectが組み込まれたHibernateはまだspring-boot-starter-data-jpaに入っていませんので、6.0.0.Beta2以降のHibernate-Coreに差し替える必要があります。
サンプルが提供されているので簡単に行えると考えていましたが、SpringBoot3以外でHibernate-Coreの差し替えを行うと次の例外が起こりSpringBootが起動しません。。サンプルの通りTiDB dialectを利用するにはSpringBoot3を利用したほうがよさそうです。
java.lang.NoClassDefFoundError: javax/persistence/EntityManagerFactory
at org.springframework.data.jpa.util.BeanDefinitionUtils.<clinit>(BeanDefinitionUtils.java:57) ~[spring-data-jpa-2.7.3.jar:2.7.3]
at org.springframework.data.jpa.repository.support.EntityManagerBeanDefinitionRegistrarPostProcessor.postProcessBeanFactory(EntityManagerBeanDefinitionRegistrarPostProcessor.java:72) ~[spring-data-jpa-2.7.3.jar:2.7.3]
at org.springframework.context.support.PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(PostProcessorRegistrationDelegate.java:325) ~[spring-context-5.3.23.jar:5.3.23]
at org.springframework.context.support.PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(PostProcessorRegistrationDelegate.java:191) ~[spring-context-5.3.23.jar:5.3.23]
at org.springframework.context.support.AbstractApplicationContext.invokeBeanFactoryPostProcessors(AbstractApplicationContext.java:746) ~[spring-context-5.3.23.jar:5.3.23]
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:564) ~[spring-context-5.3.23.jar:5.3.23]
at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:147) ~[spring-boot-2.7.4.jar:2.7.4]
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:734) ~[spring-boot-2.7.4.jar:2.7.4]
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:408) ~[spring-boot-2.7.4.jar:2.7.4]
at org.springframework.boot.SpringApplication.run(SpringApplication.java:308) ~[spring-boot-2.7.4.jar:2.7.4]
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1306) ~[spring-boot-2.7.4.jar:2.7.4]
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1295) ~[spring-boot-2.7.4.jar:2.7.4]
at com.example.TidbSpringbootJpaApplicationKt.main(TidbSpringbootJpaApplication.kt:14) ~[main/:na]
buid.gradleでは次のようにすることで差し替えることができます。
dependencies {
implementation ("org.springframework.boot:spring-boot-starter-parent:3.0.0")
implementation ("org.springframework.boot:spring-boot-starter-web:3.0.0")
implementation ("org.springframework.boot:spring-boot-starter-data-jpa:3.0.0") {
exclude group: "org.hibernate", module: "hibernate-core"
}
implementation ("org.hibernate.orm:hibernate-core:6.1.5.Final")
}
接続先(application.yml)
datasource にはDockerで定義した接続先を指定するだけで、MySQLのときと特に変わりはありません。JPAの database-platform にHibernateの差し替えで利用できるようになったTiDB dialectを指定するぐらいで特段注意する点はないかと思います。
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:4000/tidb_sample username: tidb password: tidbpassword type: com.zaxxer.hikari.HikariDataSource jpa: database-platform: org.hibernate.dialect.TiDBDialect
JPA
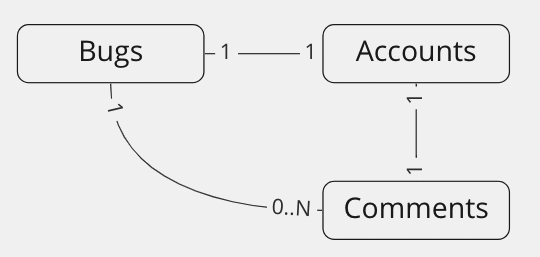
テーブルは簡単なバグトラッキングシステムをイメージした以下の3テーブルを操作することにします。
- Bugs:バグを管理するテーブル
- Comments:バグのコメントを管理するテーブル
- Accounts:アカウントを管理するテーブル
ざっくりとしたER図はこちら。
エンティティ
TiDBで auto_increment の利用ができないため自動採番を行いたい場合はシーケンスを利用する必要がありますので、 @GeneratedValue と @SequenceGenerator でシーケンスの利用を指定しています。
@Entity @Table(name = "bugs") data class Bugs( @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator="bug_id") @SequenceGenerator(name="bug_id", sequenceName="bug_id_seq", allocationSize=1) @Column(name = "bug_id") val bugId: Int?, @Column(name = "date_reported") val dateReported: Date, @Column(name = "summary") val summary: String, @Column(name = "description") val description: String, @OneToOne @JoinColumn(name = "reportedBy", referencedColumnName = "account_id") val reportedBy: Accounts, @OneToOne @JoinColumn(name = "assignedTo", referencedColumnName = "account_id") val assignedTo: Accounts, @Enumerated(EnumType.STRING) val status: Status, ) @Entity @Table(name = "comments") data class Comments( @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator="comment_id") @SequenceGenerator(name="comment_id", sequenceName="comment_id_seq", allocationSize=1) @Column(name = "comment_id") val commentId: Int?, @ManyToOne @JoinColumn(name = "bug_id", referencedColumnName = "bug_id") val bug: Bugs, @OneToOne @JoinColumn(name = "author", referencedColumnName = "account_id") val author: Accounts, val commentDate: Date, val comment: String, ) @Entity @Table(name = "accounts") data class Accounts( @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator="account_id") @SequenceGenerator(name="account_id", sequenceName="account_id_seq", allocationSize=1) @Column(name = "account_id") val accountId: Int?, @Column(name = "name") val name: String, @Column(name = "email") val email: String, )
これでHibernateの ddl-auto でテーブルを作成すると次のリソースが作成されました。
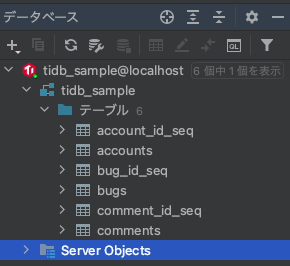
sequenceName で指定したテーブルが作られています。どうもTiDBではシーケンスはテーブルリソースとして作成され採番機能を実現しているようです。試しに account_id_seq にselectを行うと [42S02][1051] Unknown table '' とエラーが出てしまいます。 select nextval(account_id_seq); といったシーケンスを取得する関数を利用することで次の値を取得することができます。この辺はMariaDBに寄せてる感じです。
まとめ
使ってみた結果、MySQLに接続しているのとほぼ変わりなくTiDBを利用することができました。他のORマッパーでも利用することができると思いますが、TiDB dialectが吸収している差異を自力で解決する必要があるため、できるだけJPAを使うのがよさそうに思います(JPAに好き嫌いがあるとは思いますが)。
後は性能や運用面、費用で問題がなければ実運用でも十分採用することができるのではないかと感じました。2回に渡ってTiDBを調べてみましたが参考になれば幸いです。
TiDBとMySQLの機能比較
ZOZO Advent Calendar 2022 カレンダー Vol.3 の 9 日目の記事です。
久しぶりのブログ更新になります。前回からだいぶ時間が空いてしまったので定期的に書けるようにしていかないとと反省しています。。
NewDBと呼ばれる新しいデータベースが登場し利用事例が増えてきました。その中でもMySQL互換のTiDBについて耳にする機会が増えたので、MySQLとの機能比較を行ってみました。DB選定や移行検討の際にお役に立てれば幸いです。
TiDBとは
TiDBはPingCAP社が開発した分散型データベースで、RDBMSとNoSQLの機能を組み合わせたデータベースです。
MySQL互換のSQL解析機能を持っているためアプリケーションからはMySQLと同様のアクセスが可能であり、水平方向のスケーラビリティ・協力な一貫性・高可用性を兼ね備えています。
MySQLとTiDBの比較
アプリケーションから利用する際の機能比較になります。インフラ・運用面、費用などは利用する環境によってパターンが多く出てしまうため、対象外とします。
トランザクション分離レベル
(一つの表にまとめるのが困難だったので別途切り出してます...)
- ダーティリード:コミットされていないデータを別トランザクションで読めてしまう
- ノンリピータブルリード:コミットされたデータを別トランザクションが読めてしまう
- ファントムリード:取得したデータに対して別トランザクションがInsert or Deleteしてコミットすると同じ条件で読み込むとデータが増減している
MySQL8
| ダーティリード | ノンリピータブルリード | ファントムリード | |
|---|---|---|---|
| READ UNCOMMITTED | ◯ | ◯ | ◯ |
| READ COMMITTED | ◯ | ◯ | |
| REPEATABLE READ (デフォルト) |
|||
| SERAIALAZABLE |
TiDB
| ダーティリード | ノンリピータブルリード | ファントムリード | |
|---|---|---|---|
| READ UNCOMMITTED | ◯ | ◯ | ◯ |
| READ COMMITTED | ◯ | ◯ | |
| REPEATABLE READ (デフォルト) |
◯ | ||
| SERAIALAZABLE |
- MySQL(InnnoDB)はREPEATABLE READでファントムリードが発生しない
- TiDBはREPEATABLE READでファントムリードが発生する
- TiDBトランザクション分離レベル
その他
| 項目 | MySQL8 | TiDB | 備考 |
|---|---|---|---|
| DDL |
|
||
| 権限 |
|
||
| 文字コードと順序 |
|
|
|
| 索引 (index) |
|
||
| 一時テーブル (temporary) |
|
||
| ビュー (view) |
|
||
| 分割 (partition) |
|
||
| 自動採番 (auto increment) |
|
||
| 外部キー (foreign key) |
|
||
| ユニーク制約 (unique index) |
|
||
| 検査制約 (check) |
|
||
| 型 (data type) |
|||
| 結合 (join) |
|
||
| トリガー (trigger) |
|
||
| ストアドプロシージャ、関数 (procedure/function) |
|
||
| 集計関数 (window function) |
|
|
まとめ
MySQL5.7をベースにしているだけあってMySQLと同等のことが行えそうです。ただ、
- 外部キーの動作
- auto increment
は、データの整合性・値を別途取得するなど、アプリでの対応が必要となり移行の際に改修ゼロとまではいかなそうです。外部キーはプロジェクトのルールで必須となっている場合もあるかと思うので、使えないのは厳しいかもしれませんね。 とは言いつつもここまで互換性があると、書き込み性能に困っているアプリケーションの移行先にTiDBが選ばれるのも分かる気がします。近い将来、機能差異もなくなるのではないかと思うと今後の動向を注目ですね。
次回はアプリケーション(SpringBoot+JPA)からTiDBを利用する記事を書こうと思います。
ながのJava、復活へ向けて 〜一緒に運営してくれる人募集〜
これといった活動もしていないのでご存知の方はいらっしゃらないと思いますが、2年ほど前に地方JUGとして「ながの Java」を立ち上げようとしていました。
過去の記事はこちら(開催記事は前職のテックブログとして公開)
運も悪くコロナが始まってしまい勉強会どころではなくそのまま頓挫してしまう状況でした。
そして2年経過した先日、JJUG CCC 2022のアンカンファレンスで「地方JUG最近どうよ!?座談会」という話題があることを知りすぐに参加しました。
座談会の中で僕のこのツイートを拾っていただきました。
naganoは開始とともにコロナ禍になってわからなくなって進められなかった。。#jjug_ccc #jjug_ccc_unconf
— てらっち☔️ (@chichi1091) 2022年6月19日
それもあり、長野でJUGを立ち上げようとしたことを多くの方に知っていただき、応援や温かいお言葉を頂戴しました。改めてお礼させてもらいます。ありがとうございます!!
地方JUG仲間として、もし何かお手伝いできることがあればぜひ!
— YAMAKAWA, Hiroto (@gishi_yama) 2022年6月19日
11月後半から3月後半に志賀高原、野沢温泉、白馬によく行ってました!!
— 寺田佳央@クラウド・アドボケイト (@yoshioterada) 2022年6月19日
もし機会がございましたら、ぜひお声掛けくださいませ!!🙇♂️😄
ご参加ありがとうございました!話を振ればよかった、すみません・・・!長野遊びにいきたいです〜!一緒に地方JUG盛り上げていきましょう 💪
— きの子 ₍₍⁽⁽🍄₎₎⁾⁾ (@aa7th) 2022年6月19日
このチャンスを逃すわけにはいかない!ということで2年ぶりに「ながのJava」の立ち上げを目指したいと思います!!
ただ、まだどのように行っていくかは未計画です。このあたりも含め一緒に運営してくれる人をまた募集したいと思います。
(前回の反省点として一人運営は辛い厳しいというのを実感しております。。)
ご興味がある方は @chichi1091 に連絡いただけると幸いです。
ぜひぜひ地方JUGを一緒に盛り上げていきましょう!!
パーツを新調した自作PC
去年の夏休みに工作と謳って自作PCを作りました。
予算に限りもあり家にあったパーツを使いながら完成させた記事はこちら。
時間をかけてゆっくりとパーツを集め、ようやく一区切りとなったので変化した自作PCスペックになります。
| パーツ | |
|---|---|
| Core i5 10400F BOX(6C/12T) | |
| PRIME B460M-A (B460 1200 MicroATX) | |
| M.2 SSD 1TB | NEW |
| CMK32GX4M2A2666C16 (DDR4 PC4-21300 16GB 2枚組) | |
| KRPW-L5-500W/80+ (500W) | |
| CA-1J4-00S1WN-00 (Versa H18 MicroATX アクリル) | |
| GIGABIT GTX1650 | NEW |
| LED PCファン×3 | NEW |
グラボが新しくなったので軽めのゲームもできるようになりました(Ubuntuなので限られてしまいますが)
せっかくパワーアップさせたのでもっと活用してあげねば